
FLAMe’s capacity to provide a strong base for additional fine-tuning is one of its most notable qualities.
Foundational Large Autorater Models (FLAMe), a family of foundational autorater models developed by Google DeepMind, are capable of completing a range of quality assessment tasks. The purpose of FLAMe is to mitigate the growing difficulties and expenses linked to the assessment of LLM results by humans.
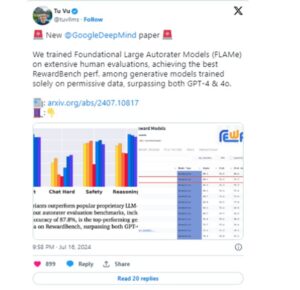
This new family of autorater models represents a major breakthrough in the industry, outperforming the current proprietary models on several criteria. Over 100 different quality assessment tasks totaling 5 million human judgments, FLAMe is trained. This large dataset guarantees that FLAMe can generalize to a broad range of activities, as it was assembled using publically available human evaluations.
Notably, on a number of important evaluation criteria, FLAMe versions have outperformed industry leaders like GPT-4 and Claude-3.
One of FLAMe’s most notable qualities is its capacity to provide a solid base for additional fine-tuning. On the RewardBench benchmark, for example, the FLAMe-RM variant—which was optimized for reward modeling evaluation—achieved an astounding 87.8% accuracy. GPT-4-0125 and GPT-4o, with scores of 85.9% and 84.7%, respectively, are not as good as this performance.
Furthermore, a more computationally efficient variant, FLAMe-Opt-RM, achieves competitive results with a substantially smaller amount of training data.
In addition to performing better than other methods, FLAMe tackles prejudice in LLM autoraters. The models have demonstrated a notable decrease in bias on the CoBBLEr autorater bias benchmark, indicating increased reliability in identifying high-quality responses across a range of applications, such as programming prompts and code production.
The creation of FLAMe demonstrates Google DeepMind’s dedication to developing AI solutions that are easily accessible. The team hopes to encourage more studies into reusable human evaluations and the development of efficient LLM autoraters by making the data collection freely available. This project opens the door for more effective and fair AI development procedures while also improving the accuracy of automated assessments.













