
The enormous Llama 3.1 405B model is still freely available and open source, challenging GPT-4 and Claude 3.5.
Llama 3.1 405B, the largest open-source AI system ever, is a massive 405 billion parameter model that Meta has released.
Although Meta recently introduced the Llama 3 model line in April, the company has been working on a massive model that contains 400 billion parameters.
With 405 billion parameters, the massive AI system that the business unveiled was dubbed “in a class of its own” by Meta.
With an updated Stack API, customers may effortlessly integrate the robust underlying model provided by Meta’s latest release, which is ideal for use cases like multilingual conversational agents or lengthy text summaries.
The AI research community will be able to “unlock new workflows, such as synthetic data generation and model distillation,” according to Meta, thanks to the new gigantic model.
The large Llama model is intended to compete, while staying open source, with foundation-level models such as Anthropic’s new Claude 3.5 and OpenAI’s GPT-4.
CEO of Meta Mark Zuckerberg declared on Facebook, “I think the Llama 3.1 release will be an inflection point in the industry where most developers begin to primarily use open source, and I expect that approach to only grow from here.”
Dimensions and Functions
The largest published Llama model had 70 billion parameters prior to this publication.
With 175 billion parameters, OpenAI’s GPT-3 pales in comparison to the new Llama 3.1 405B.
Although the size of GPT-4 has never been disclosed by OpenAI, industry conjecture indicates that it may contain trillions of parameters. However, because of the company’s secrecy, this is still unverified.
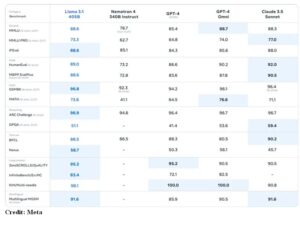
Meta claims that their new Llama model outperforms closed systems like GPT-4 in a variety of tasks, such as general knowledge, steerability, math, tool use, and multilingual translation, even if it might be smaller than OpenAI’s model.
According to benchmark findings, Llama 3.1 405B performs competitively on industry-standard tests like MMLU and HumanEval, but outperforms models like Claude 3.5 and GPT-4o at tests like GSM8K and Nexus.













